Сучасна розробка додатків змінилася, щоб включити не лише інструменти, які пропонують чудовий досвід розробника (DX), але й розумний баланс між простим початком роботи та шляхом до виробництва. Саме це почуття надихнуло на випуск набору Amplify AI. Ця абстракція над звичайними завданнями штучного інтелекту, такими як розмова з великою мовною моделлю (LLM) і генерування вмісту з підказки, означає, що розробники швидше виходять на ринок і уникають написання шаблонного коду.
У цій публікації ми вийдемо за межі початкового досвіду та використаємо безсерверну базу даних Postgres від Neon для отримання даних про продукт замість моделі бази даних за замовчуванням від Amplify. Роблячи це, ми спростимо код, необхідний для спілкування з LLM, використовуючи пошуково-розширену генерацію (RAG).
Огляд програми
Загальне звернення до споживачів додатків полягає в тому, як штучний інтелект використовується для вдосконалення існуючого продукту, а не для конкуренції з ним. Простий і ефективний спосіб продемонструвати це – створити чат-бота, з яким клієнти зможуть взаємодіяти. У реальному сценарії це не завадить клієнту робити покупки самостійно, але надасть йому орієнтири до покупки за допомогою природної мови.

З точки зору архітектури, щоразу, коли користувач відвідує програму, він може спілкуватися з нашим ботом на базі LLM. Ці моделі навчаються на загальних даних, хоча в нашому випадку використання ми хотіли б, щоб вони також знали про наші дані про продукт. Інформація про продукт може змінитися в будь-який час, тому важливо отримувати інформацію з нашої бази даних. Ця ідея вибору між загальною інформацією чи доступом до конкретних даних є потужною та реалізується за допомогою інструменту (також відомого як «виклик функції»).
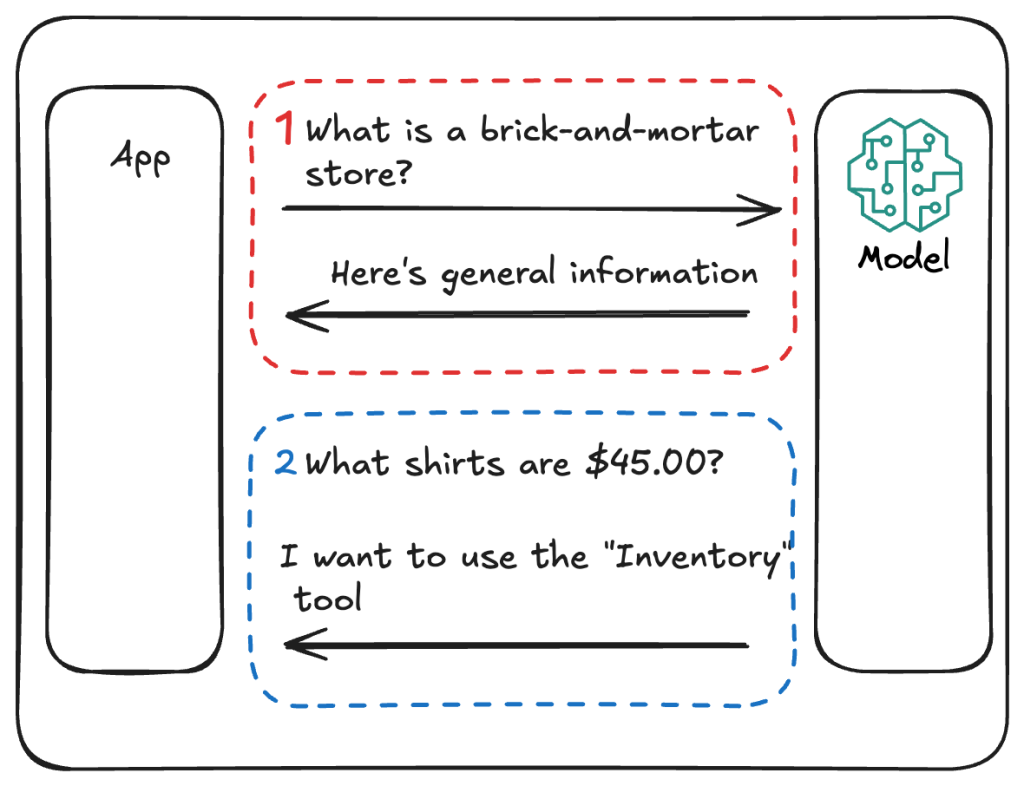
Важливо пам’ятати, що коли LLM вирішує використовувати інструмент, він не звертається до ваших даних від вашого імені. Це просто передача того, який інструмент буде працювати найкраще за підказкою користувача. Звідти програми вирішують, яку функцію вони хочуть викликати.
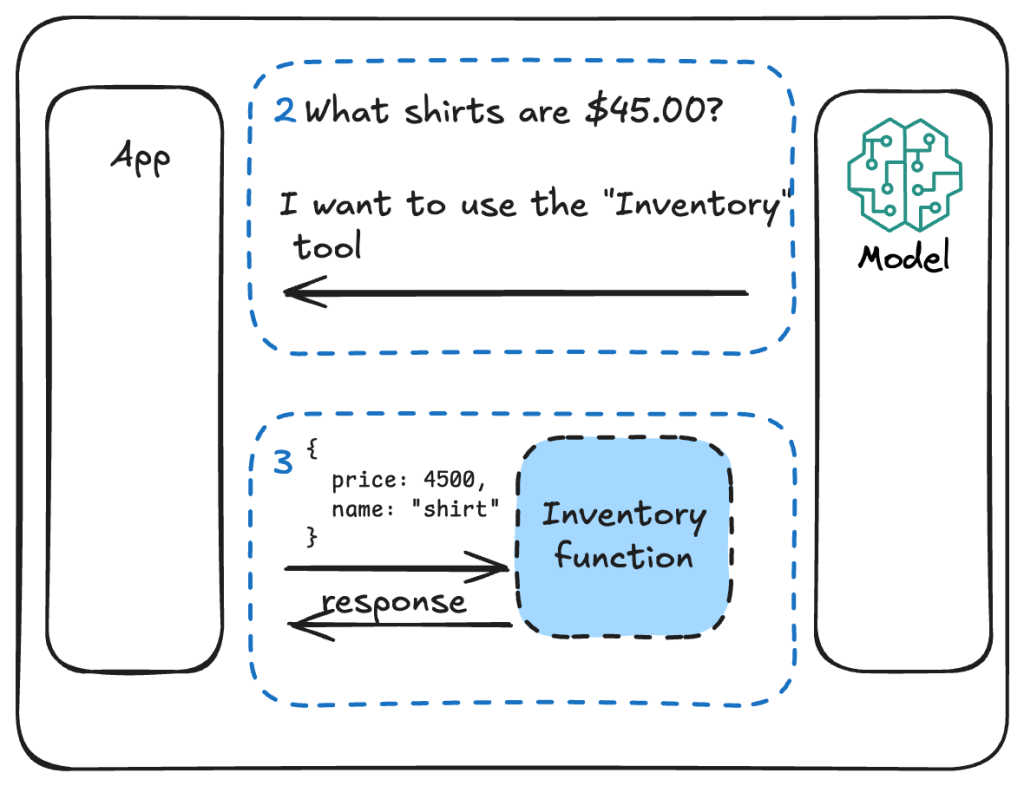
Відповідь від цієї функції потім надсилається назад до LLM і форматується як природна мова для кінцевого користувача.
Як можна собі уявити, організовувати цей шаблон самостійно може бути не тільки втомливим, але й призвести до помилок. На щастя, цей недиференційований важкий набір забезпечує комплект Amplify AI за замовчуванням.
Зокрема, наш проект використовуватиме Amazon Bedrock із Claude 3.5 Haiku LLM, оскільки ця модель постачається з інструментальною підтримкою. Amplify дозволить нам вказати інструмент, який відповідає одній із наших баз даних. У нашому випадку це буде наша база даних Neon Postgres, що містить інформацію про наш продукт.
Створення безсерверних баз даних Postgres за допомогою Neon
Можливість підключатися до існуючих джерел даних означає, що розробники можуть використовувати потужність самоаналізу схеми Amplify за межами Amazon DynamoDB, бази даних за замовчуванням, щоб генерувати операції CRUD від їх імені. Налаштувати базу даних Neon просто. Після створення облікового запису вам буде запропоновано створити проект.
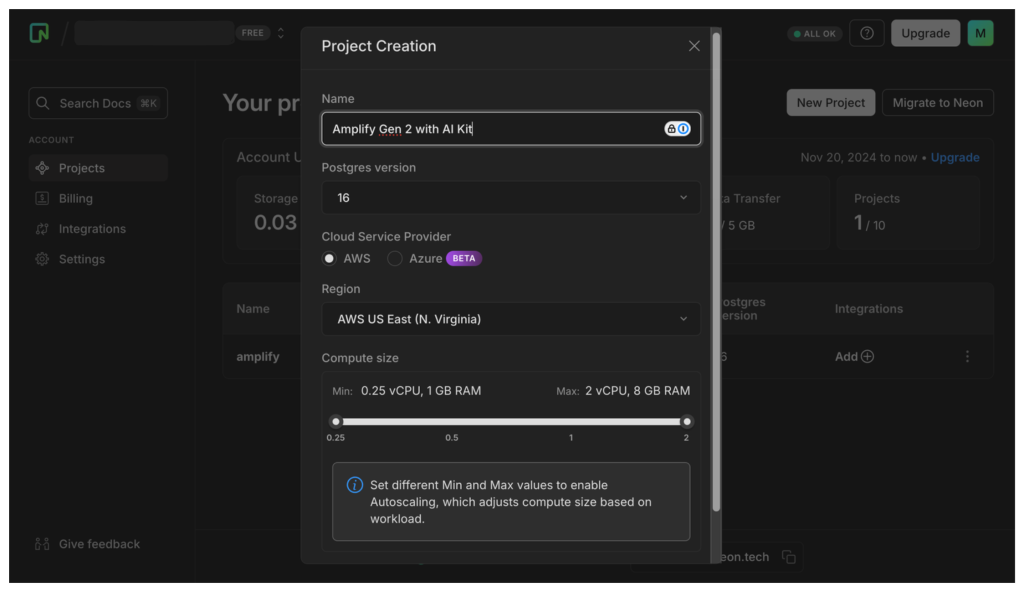
Neon підтримує проекти на основі гілок, подібні до git. Це копії main відділення. У моєму випадку у мене є можливість створити гілку під назвою dev/mtliendo . Це рекомендовано, але не обов’язково. У будь-якому випадку ви захочете скопіювати рядок підключення для цієї гілки, оскільки це буде важливо в наступних розділах.
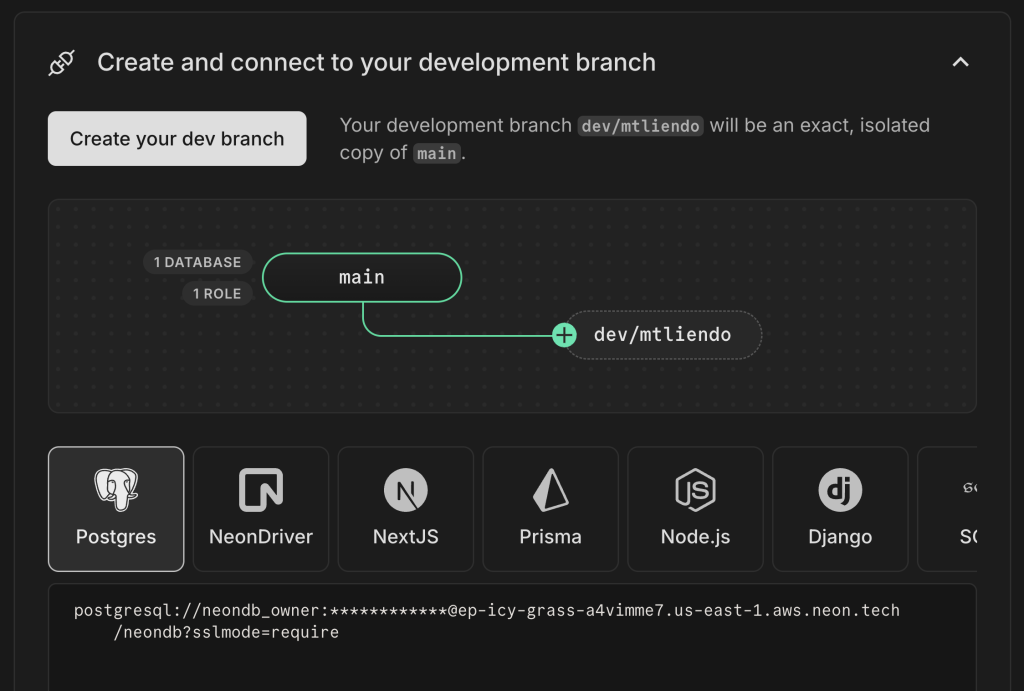
Наша база даних за замовчуванням налаштована, однак вона ще не містить таблиць. Точніше, схема нашої таблиці ще не визначена. Ви будете засмучені, дізнавшись, що я не знаю, як писати SQL. На щастя, Neon вирішує це за допомогою функції «Generate with AI». У чаті з їхнім LLM про те, що я хотів би зробити, і відповідь буде згенерована для мене.
У їх редакторі SQL я пишу наступне:
Створіть схему таблиці під назвою «Продукти». Кожен продукт має випадковий ідентифікатор, поле «оновлено в», яке є датою та часом, поле «створено в», яке є датою та часом, поле «ціна в центах», яке є числом, «ім’я», і «опис».
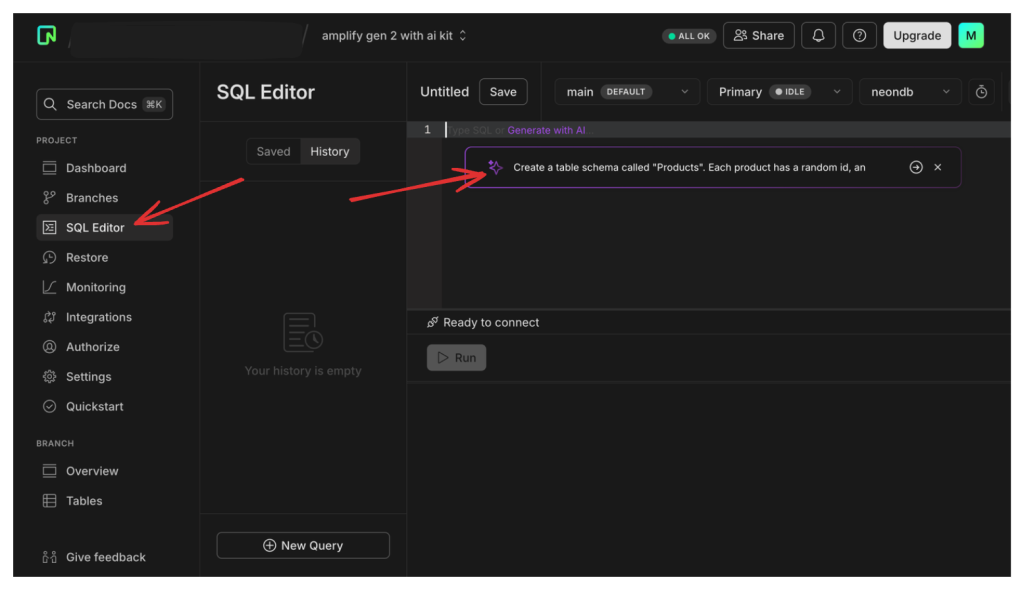
Після виконання підказки я отримав таку відповідь:
CREATE TABLE Products (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
updated_at TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP,
created_at TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP,
price_in_cents INTEGER NOT NULL,
name VARCHAR(255) NOT NULL,
description TEXT
);
Звідти я маю можливість внести зміни в код і запустити команду один раз, коли я зрозумію синтаксис.
Щоб перевірити, чи все налаштовано належним чином, клацніть посилання «Таблиці» на бічній панелі, щоб перевірити схему, а також заповнити нашу базу даних.
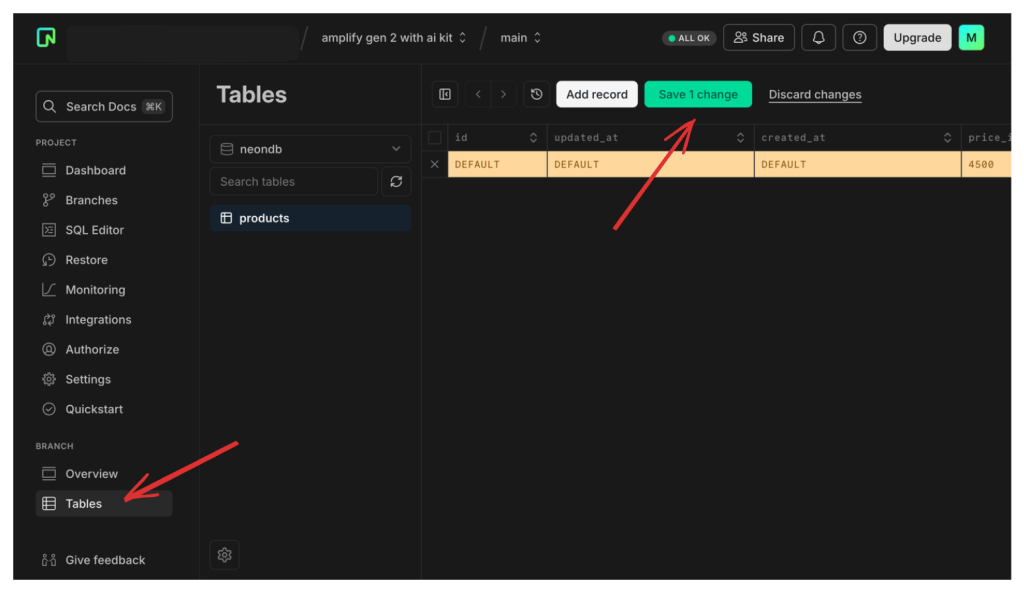
Для цього проекту я додав кілька елементів до бази даних. Також не забудьте скопіювати рядок підключення до нашої бази даних, оскільки він нам знадобиться в наступному розділі. Рядок підключення можна знайти в розділі «Огляд» бічної панелі.
Покращення Amplify Gen 2 за допомогою AI Kit
AWS Amplify — це найпростіший спосіб підключити ваші зовнішні програми до серверної частини на базі AWS. Припустимо, що програму, що використовує фреймворк JavaScript, як-от NextJS, уже створено, створіть файли Amplify, виконавши таку команду в корені проекту:
npm create amplify
Це встановить залежності Amplify, а також створить amplify каталог. Перш ніж змінювати код у цьому каталозі, ми встановимо кілька інших залежностей, необхідних для набору Amplify AI:
npm i @aws-amplify/ui-react @aws-amplify/ui-react-ai
Це компоненти інтерфейсу користувача, які ми незабаром використаємо.
Перш ніж це зробити, ми дозволимо Amplify перевірити нашу базу даних за допомогою products таблицю, щоб ми могли використовувати її в нашому сервері. Перший крок — зберегти наш рядок підключення як секрет. Цей секрет зберігається в сховищі параметрів у AWS Systems Manager. На щастя, Amplify пропонує простий спосіб зробити це.
У вашому терміналі виконайте таку команду:
npx ampx sandbox secret set SQL_CONNECTION_STRING
Це встановлює секретне значення SQL_CONNECTION_STRING і запитує значення. Звідси вставте рядок підключення, скопійований з Neon, і натисніть enter.
У цьому розділі припускається, що на вашій локальній машині вже налаштовано AWS Amplify. Якщо вам потрібно налаштувати Amplify, зверніться до документації, щоб отримати інструкції.
Після того, як секрет буде збережено, ми можемо наказати Amplify перевірити нашу базу даних і створити операції CRUD, які ми можемо використовувати в нашій зовнішній програмі:
npx ampx generate schema-from-database --connection-uri-secret SQL_CONNECTION_STRING --out amplify/data/schema.sql.ts
Виконання цієї команди створить a schema.sql.ts файл у amplify/data папку. Важливо не змінювати цей файл, оскільки ним керує Amplify. Після виконання цієї команди файл має виглядати так, як на знімку екрана нижче:
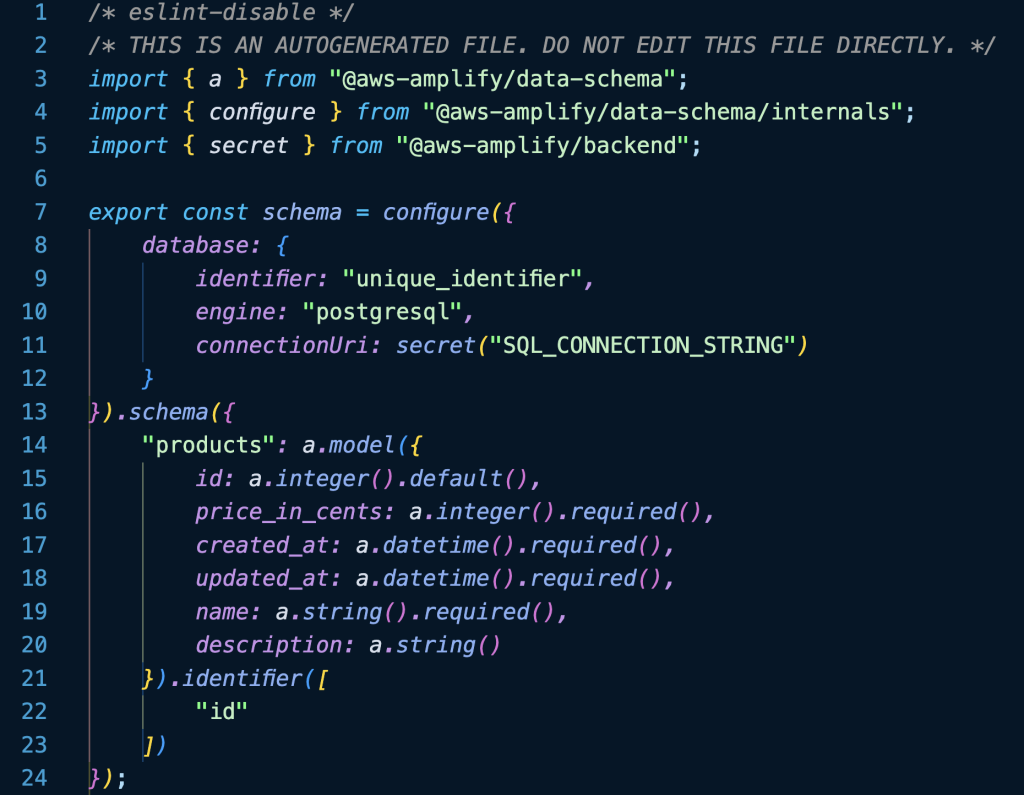
Amplify використовує цей файл, щоб зіставити нашу базу даних Postgres у формат, який працює з нею a.model метод.
Перегляньте документацію, якщо хочете дізнатися, що Amplify робить за лаштунками, щоб це працювало.
import { type ClientSchema, defineData, a } from '@aws-amplify/backend'
import { schema as generatedSqlSchema } from './schema.sql'
const sqlSchema = generatedSqlSchema.setAuthorization((models) => [
models.items.authorization((allow) => [allow.authenticated().to(['read'])]),
])
const schema = a.schema({
chat: a
.conversation({
aiModel: a.ai.model('Claude 3.5 Haiku'),
systemPrompt:
'You are a helpful assistant, that focuses on selling and upselling merchandise',
tools: [
a.ai.dataTool({
name: 'MerchQuery',
description:
'Search for questions regarding merchandise, shopping apparel, and item prices.',
model: a.ref('items'), //! This refers to the name of our table
modelOperation: 'list',
}),
],
})
.authorization((allow) => allow.owner()),
})
const combinedSchema = a.combine([sqlSchema, schema])
export type Schema = ClientSchema
export const data = defineData({ schema: combinedSchema })
Тепер, коли наша база даних Neon є в нашій програмі, ми можемо імпортувати її в amplify/data/resource.ts файл і поєднайте його з можливостями розмови комплекту Amplify AI. Давайте розберемо, що відбувається в цьому файлі:
- Рядок 4: Тут ми призначаємо правила авторизації для нашого
productsстіл від Neon. У цьому випадку можуть працювати лише користувачі, які ввійшли в системуreadоперації проти нього. - Рядок 8: Створюємо ідентифікатор під назвою
chat. Це розмовний бот, який приймає, як мінімум, ім’я LLM і підказку про те, як він повинен поводитися. Нічого не варто, що назви моделей введені та доступні в Intellisense. - Рядок 13: Ми вдосконалюємо нашого бота, надаючи йому інструмент. Назву та опис визначаємо ми, тоді як
modelмає посилатися на назву нашої бази даних Neon. Наразі єдиний, що підтримуєтьсяmodelOperationєlist. - Рядок 22: Цей рядок пропонує зрозуміти, що відбувається за лаштунками. Таблиця DynamoDB зберігає історію розмов користувачів, які ввійшли в систему.
Поєднуючи всі ці елементи, ми отримуємо повністю кероване рішення для безпечної розмови з LLM, який знає про елементи в нашій базі даних.
Щоб перевірити наше рішення, ми спершу розгорнемо серверну частину AWS, виконавши таку команду:
npx ampx sandbox
Після розгортання ми можемо імпортувати нашу конфігурацію Amplify і налаштувати наш клієнтський додаток, щоб використовувати конфігурацію, компоненти інтерфейсу користувача та хуки, надані Amplify:
import { generateClient } from 'aws-amplify/api'
import { Schema } from '@/amplify/data/resource'
import { useEffect } from 'react'
import { Amplify } from 'aws-amplify'
import awsconfig from '@/amplify_outputs.json'
import { withAuthenticator } from '@aws-amplify/ui-react'
import { AIConversation, createAIHooks } from '@aws-amplify/ui-react-ai'
import '@aws-amplify/ui-react/styles.css'
Amplify.configure(awsconfig)
const client = generateClient()
const { useAIConversation } = createAIHooks(client)
Після налаштування весь зовнішній інтерфейс із чатом, інформуванням про розмову, потоковою трансляцією, станами завантаження та автентифікацією можна налаштувати приблизно в 20 рядках коду:
function Home() {
const [
{
data: { messages },
isLoading,
},
handleSendMessage,
] = useAIConversation('chat')
return (
)
}
export default withAuthenticator(Home)
Не соромтеся порівняти код вище з першим знімком екрана в цій публікації. Новий AIConversation Компонент комплекту Amplify AI надає повний користувальницький інтерфейс чату, водночас демонструючи різні елементи для подальшого налаштування відповідно до ваших потреб.
Висновок
У цьому дописі ми обговорили деякі складності створення програм повного стеку, які підтримують спілкування з LLM за допомогою генерації з доповненим пошуком (RAG). Потім ми побачили, як новий набір штучного інтелекту від AWS Amplify значно спрощує цей досвід, абстрагуючи шаблони, дозволяючи розробникам зосередитися на частинах, які справді роблять додаток іншим. Як ми бачили, ця легкість у налаштуванні не відбувається за рахунок розширюваності. Ми довели це, створивши базу даних Postgres з Neon і використовуючи її разом із нашим інструментом.
Набір Amplify AI є ще одним кроком вперед у створенні масштабованих безпечних додатків повного стеку. Щоб ознайомитися з набором Amplify AI у вашій програмі, відвідайте документацію та почніть роботу вже сьогодні.