

Інтелект коду стрімко зріс завдяки вдосконаленню великих мовних моделей (LLM). Ці моделі все частіше використовуються для завдань автоматизованого програмування, таких як генерація коду, налагодження та тестування. Завдяки можливостям, що охоплюють кілька мов і доменів, LLMs стали ключовими інструментами для просування розробки програмного забезпечення, науки про дані та вирішення обчислювальних проблем. Еволюція LLM змінює підхід до складних завдань програмування та їх виконання.
Однією з важливих областей для вдосконалення поточного ландшафту є потреба в комплексних тестах, які точно відображають реальні вимоги до програмування. Існуючі набори оціночних даних, такі як HumanEval, MBPP і DS-1000, часто вузько зосереджені на конкретних областях, як-от розширені алгоритми чи машинне навчання, не враховуючи різноманіття, необхідне для повного програмування. Крім того, ці набори даних можуть бути більш розширеними для оцінки багатомовності та можливостей, що охоплюють домен, необхідних для розробки програмного забезпечення в реальному світі. Ця прогалина є основною перешкодою для ефективного вимірювання та підвищення ефективності LLM.
Дослідники з ByteDance Seed і MAP представили FullStack Bench, тест, який оцінює LLM в 11 різних областях застосування та підтримує 16 мов програмування. Тест включає в себе аналіз даних, настільну та веб-розробку, машинне навчання та мультимедіа. Крім того, вони розробили SandboxFusion, уніфіковане середовище виконання, яке автоматизує виконання та оцінку коду кількома мовами. Ці інструменти спрямовані на забезпечення цілісної основи для тестування LLM у реальних сценаріях та подолання обмежень існуючих тестів.
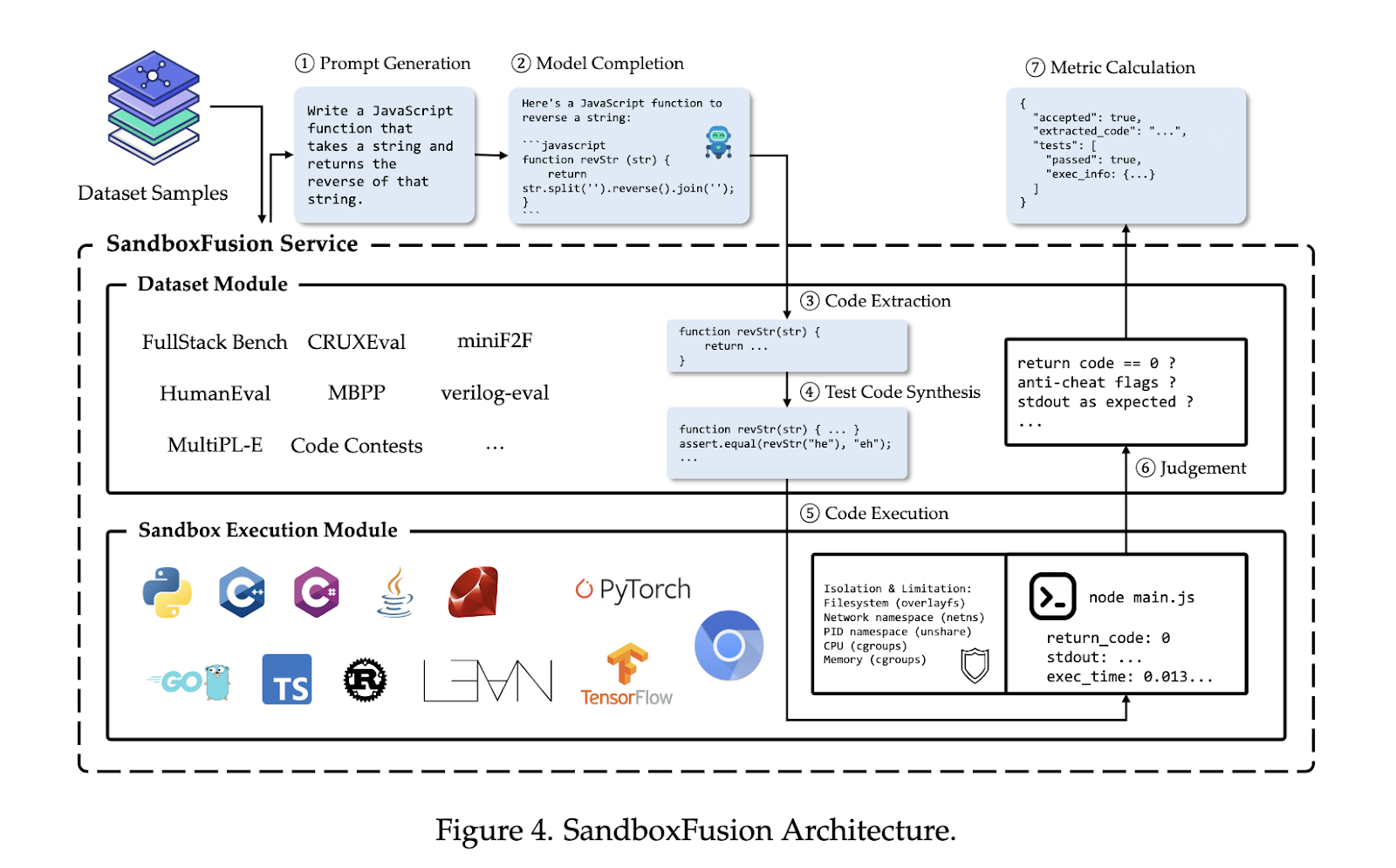
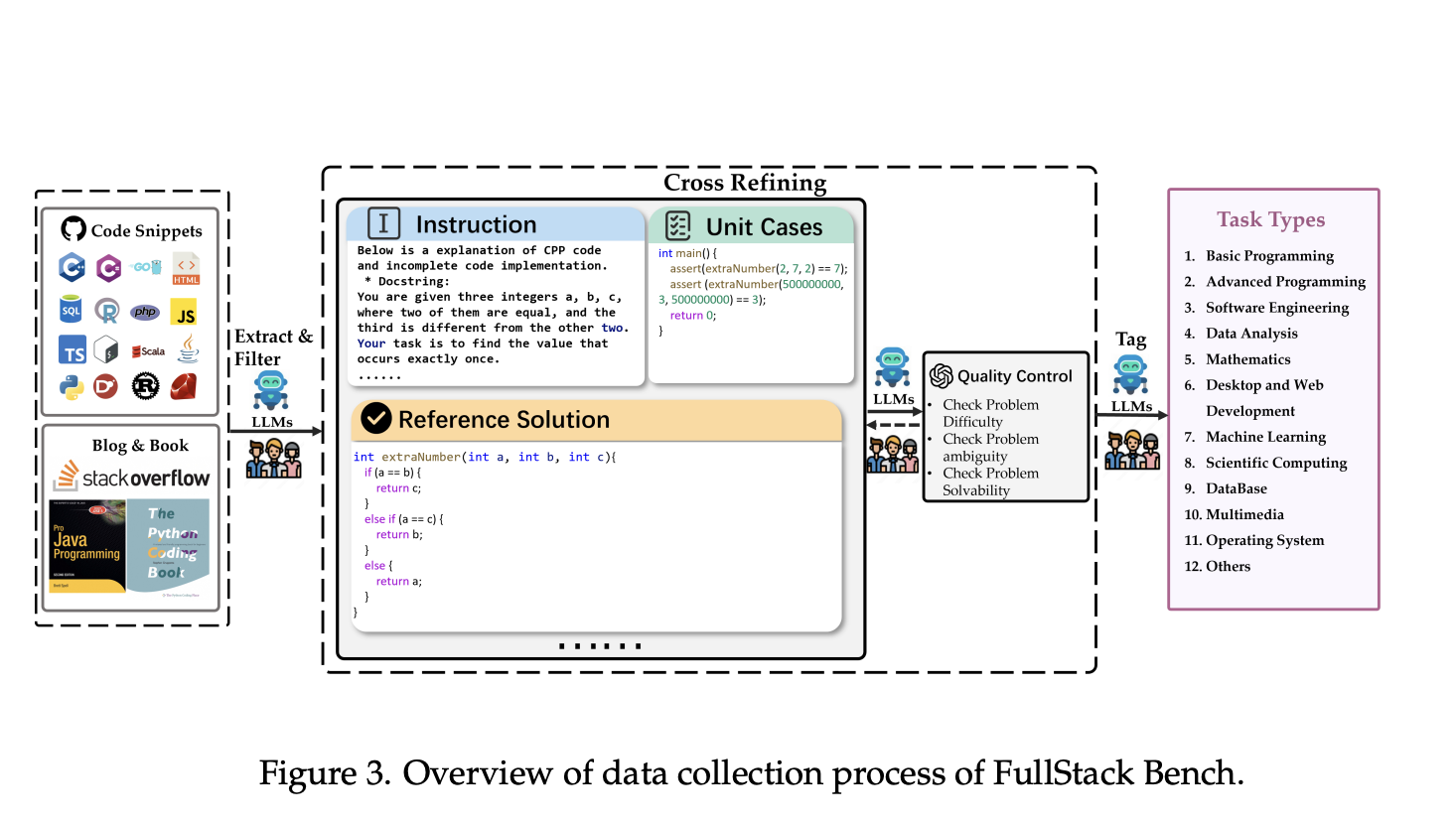
Набір даних FullStack Bench містить 3374 задачі, кожна з яких супроводжується прикладами модульного тестування, еталонними рішеннями та класифікаціями легкої, середньої та важкої складності. Проблеми були підібрані за допомогою поєднання людського досвіду та процесів за допомогою LLM, що забезпечувало різноманітність і якість дизайну питання. SandboxFusion підтримує виконання проблем FullStack Bench, створюючи безпечні ізольовані середовища виконання, які відповідають вимогам різних мов програмування та залежностей. Він підтримує 23 мови програмування, забезпечуючи масштабоване та універсальне рішення для порівняльного аналізу LLM на наборах даних за межами FullStack Bench, включаючи такі популярні тести, як HumanEval і MBPP.
Дослідники провели масштабні експерименти, щоб оцінити продуктивність різних LLM на FullStack Bench. Результати виявили помітні відмінності в продуктивності в різних доменах і мовах програмування. Наприклад, у той час як деякі моделі продемонстрували потужні базові можливості програмування та аналізу даних, інші потребували допомоги у виконанні завдань, пов’язаних із мультимедіа та операційною системою. Pass@1, основний показник оцінки, різнився в різних доменах, висвітлюючи проблеми адаптації моделей до різноманітних і складних завдань програмування. SandboxFusion виявився надійним і ефективним інструментом оцінювання, значно перевершуючи існуючі середовища виконання в підтримці широкого діапазону мов програмування та залежностей.
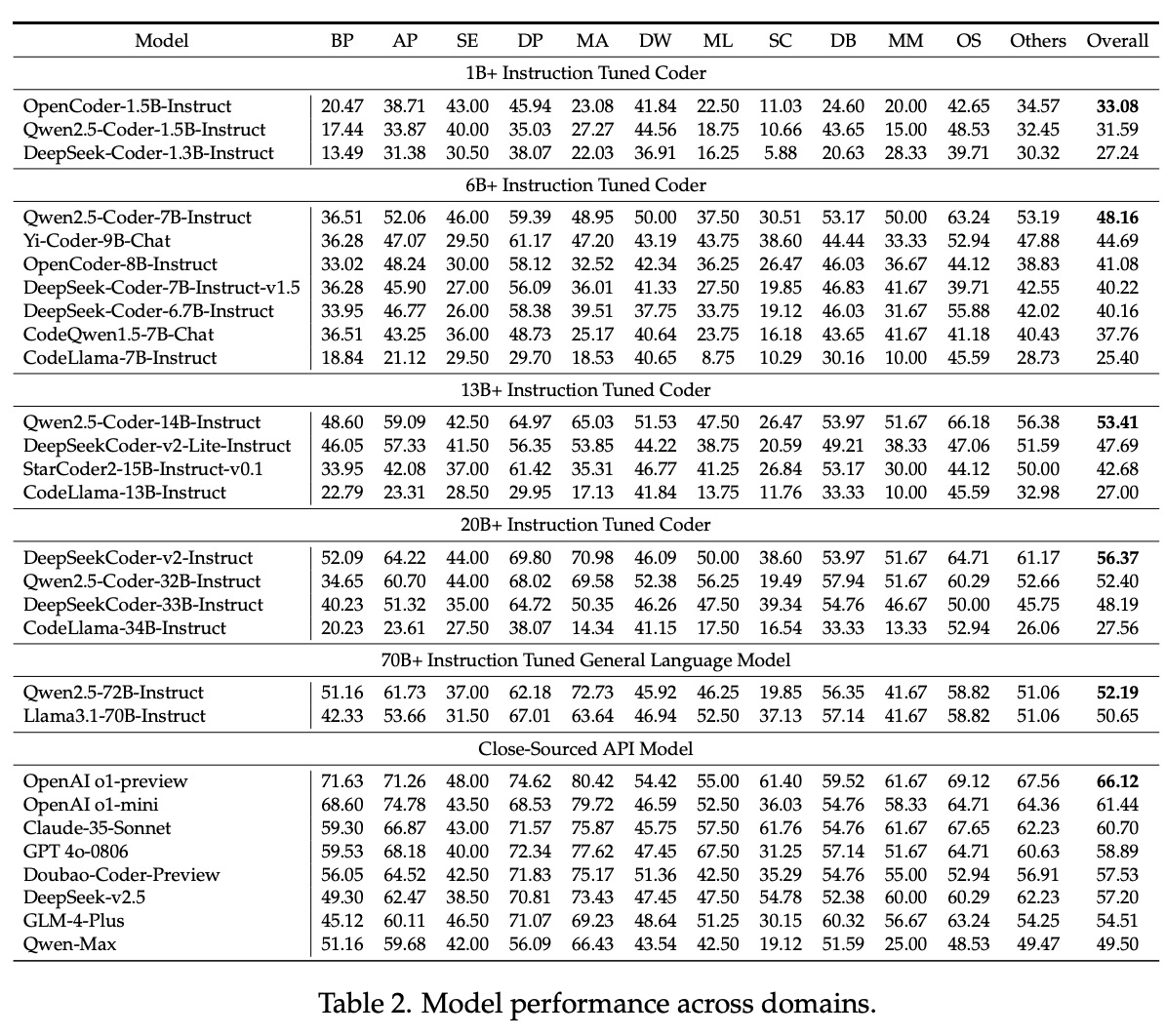
Також було проаналізовано закони масштабування, які показали, що збільшення параметрів загалом покращує продуктивність моделі. Однак дослідники спостерігали зниження продуктивності деяких моделей на вищих масштабах. Наприклад, серія Qwen2.5-Coder досягла максимуму при параметрах 14B, але продемонструвала падіння продуктивності при 32B і 72B. Це відкриття підкреслює важливість балансування розміру моделі та ефективності для оптимізації продуктивності LLM. Дослідники спостерігали позитивну кореляцію між показниками компіляції коду та показниками успіху тестування, наголошуючи на необхідності точної та безпомилкової генерації коду.
FullStack Bench і SandboxFusion разом представляють значні досягнення в оцінюванні LLM. Ураховуючи обмеження існуючих тестів, ці інструменти дозволяють більш комплексно оцінювати можливості LLM у різних сферах і мовах програмування. Це дослідження закладає основу для подальших інновацій у розробці коду та підкреслює важливість розробки інструментів, які точно відображають реальні сценарії програмування.
Виїзд в Папір, Лава FullStack, і SandboxFusion. Вся заслуга в цьому дослідженні належить дослідникам цього проекту. Крім того, не забувайте слідкувати за нами Twitter і приєднайтеся до нашого Телеграм канал і LinkedIn грвгору. Якщо вам подобається наша робота, ви будете любити нашу інформаційний бюлетень.. Не забудьте приєднатися до нашого 60k+ ML SubReddit.
🚨 [Must Attend Webinar]: «Перетворіть докази концепції в готові до виробництва програми та агенти штучного інтелекту» (підвищено)
Ніхіл є стажистом-консультантом у Marktechpost. Він отримує інтегрований подвійний ступінь з матеріалів в Індійському технологічному інституті, Харагпур. Ніхіл — ентузіаст ШІ/ML, який постійно досліджує застосування в таких галузях, як біоматеріали та біомедична наука. Маючи великий досвід у матеріалознавстві, він досліджує нові досягнення та створює можливості для внеску.
🚨🚨БЕЗКОШТОВНИЙ ВЕБІНАР зі штучним інтелектом: «Швидке відстеження ваших програм LLM за допомогою deepset & Haystack» (підвищено)


